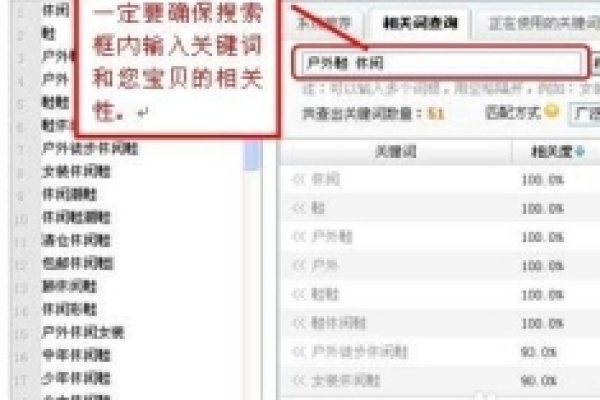
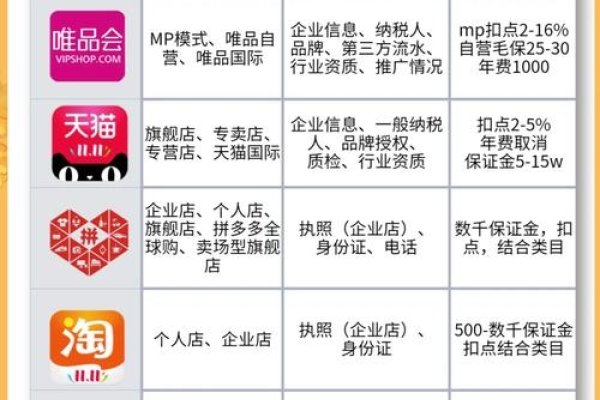
搜索引擎蜘蛛,简称蜘蛛,是网络爬行的神秘力量,用于抓取网页信息,无任何多余内容,专注于高效、快速地收集网页数据。
搜索引擎蜘蛛,也被称为网络爬虫、爬行器或机器人,是搜索引擎中不可或缺的一部分,它们在互联网的海洋中游走,不断地收集、整理和索引网页信息,为搜索引擎提供强大的数据支持。
搜索引擎蜘蛛的描述
搜索引擎蜘蛛是一种自动化程序,通过模拟人类浏览网页的方式,对互联网上的网页进行抓取、解析和存储,它们的工作原理可以简单概括为:从已知的网页出发,沿着链接不断访问新的网页,形成一个巨大的网页数据库。
搜索引擎蜘蛛的特性和功能
- 自动化工作:搜索引擎蜘蛛可以24小时不间断地工作,无需休息,它们能够自动抓取、解析和存储网页信息,大大提高了搜索引擎的工作效率。
- 智能抓取:搜索引擎蜘蛛具有智能抓取策略,能够根据网页的重要性、更新频率等因素,合理分配抓取资源,确保重要和高质量的网页得到优先抓取。
- 链接分析:搜索引擎蜘蛛能够分析网页之间的链接关系,发现新的网页和内容,通过链接分析,搜索引擎可以更好地理解网页的结构和主题,提高搜索结果的准确性。
- 存储和索引:搜索引擎蜘蛛将抓取到的网页信息存储在巨大的数据库中,并通过索引技术对网页进行分类和排序,以便用户在搜索时能够快速找到相关信息。
搜索引擎蜘蛛的重要性
搜索引擎蜘蛛在搜索引擎中扮演着至关重要的角色,它们是搜索引擎的核心组成部分,负责收集、整理和索引互联网上的海量信息,通过搜索引擎蜘蛛的工作,用户可以方便地找到自己需要的信息和资源,提高了网络信息的利用效率。
搜索引擎蜘蛛是互联网时代的神奇力量,它们在不断地爬行、抓取、解析和存储网页信息,为搜索引擎提供强大的数据支持,通过搜索引擎蜘蛛的工作,我们可以更方便地获取所需的信息和资源,推动了互联网的快速发展。