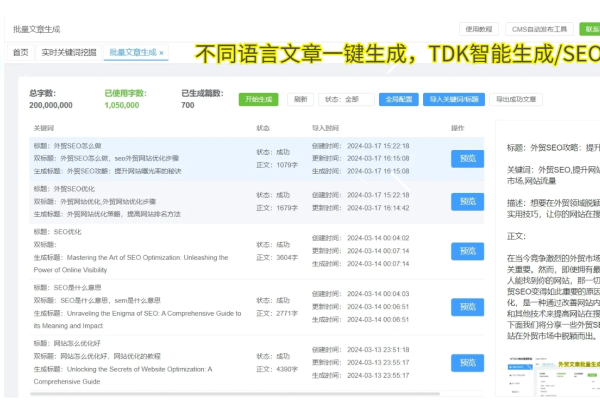
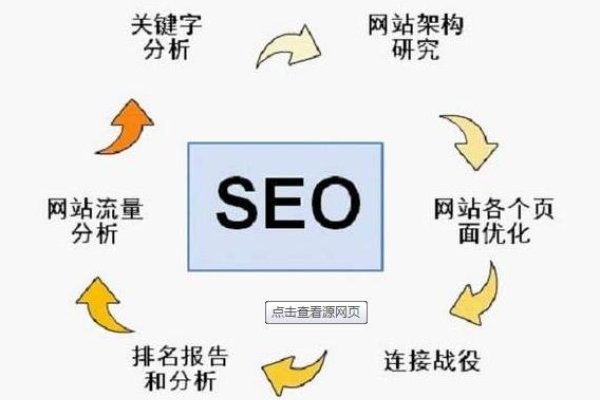
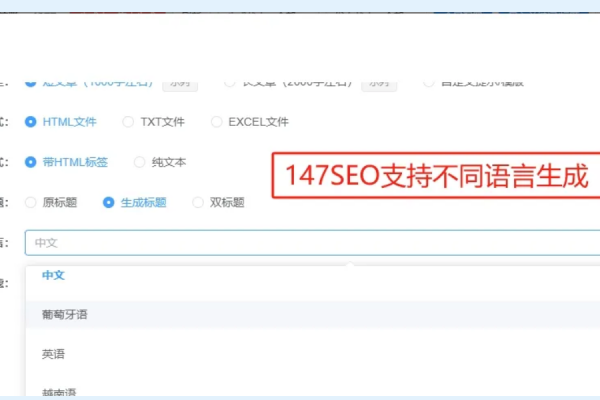
搜索引擎通过爬行技术获取网页信息,进行筛选处理后建立庞大的索引库,用户查询时,搜索引警快速准确地返回相关度高的信息,整个工作流程体现了搜索引擎对效率与精准度的追求,反映出互联网技术不断创新和发展的趋势。
搜索引擎的主要工作过程包括抓取、存储、页面分析、索引和检索等几个主要过程,也即常说的抓取、过滤、收录、排序四个过程,下面详细讲解每个过程和其影响因素:
抓取网页
百度搜索引擎使用自己的网页抓取程序即爬虫(Spider),爬虫顺着网页中的超链接不断从一个网站爬到另一个网站通过超连接分析连续访问并抓取更多网页这些被抓取的网页被称之为网页快照,数据抓取系统像网络蜘蛛一样从种子URL开始通过超链接不断发现新页面确保数据来源的稳定和全面主要由链接存储选取DNS解析调度分析和存储等组件构成 。
二、过滤网页
对于搜索引挚来说由于互联网上大量的垃圾信息和重复信息存在因此需要对爬取的数据进行预处理以便提供给用户高质量的搜索结果这个过程被称为过滤或清洗内容的过程 。
三、建立索引区
经过上述处理后互联网上的所有文字将被转换成关键词存入一个大的数据库中供以后查询调用这个数据库就叫做搜索引擎的“索引”,在大型搜索引擎中如百度的索引库每天新增数十亿条网址及相关的网页资料数量极其庞大且增长迅速,随着互联网的膨胀索引的数量也随之增加以满足用户的各种需求 。 四、提供检索服务 当用户输入关键字进行查询时搜索引擎会先在自身的海量数据库中寻找匹配的信息然后按照一定的排名规则将结果展示给用户,这一过程涉及到复杂的算法和技术以确保结果的准确性和相关性,同时为了提高用户体验还需要考虑其他因素比如响应速度服务器性能等等 ,其中影响排名的关键因素包括但不限于以下几点 :外部链接的质量和数量提交网站的频率和内容质量以及目标受众的需求和行为习惯等因素都可能影响到最终的搜索结果排名 。 总之百度搜索引攀的工作原理是一个复杂而高效的系统涉及多个模块协同工作以提供最准确和最相关的信息满足用户的需求 。
五 、总结概括一下几个要点 (可根据实际情况酌情删减) 1. 百度搜索引擎主要通过爬行技术获取网页信息并通过蜘蛛跟踪链接实现数据的实时更新和维护; 2 . 在获取信息后会对数据进行初步筛选处理去除冗余和低质量的内 容保证信息的真实性和可信度 ; 3 . 建立庞大的索引库方便后续查找和提取相关信息 ; 4 . 根据用户需求快速准确地返回相关度高的信息并提供友好的用户界面以方便用户使用体验 ,整个工作流程体现了搜索引擎对效率与精准度的追求同时也反映出互联网技术不断创新和发展的趋势 。